Deepmind learns about the art of coding
DeepMind: Reinforcement Learning Can Learn to Write Words and Code by Sorting Lists When You’re Trying to Play Chess
Reinforcement learning is a technique that Deepmind uses to help their artificial intelligence improve in chess and Go. This type of AI learns by doing. It works by treating a given task like a game, in which rewards are earned for smart moves that increase the program’s efficiency. The system works to maximize the reward, which can result in a Go strategy or quicker assembly program. The type of data that can be found in large language models like GPT-4 is not the sort of data used to learn how to write words or code. It makes producing writing that mirrors the internet or producing common segments of code easier. But it’s not so good at producing novel, state-of-the-art solutions to coding challenges the AI has never seen before.
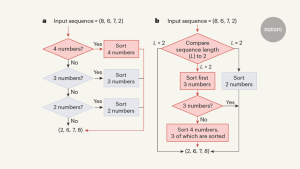
The neural networks rewarded the programs for speed, not only on correctness. Mankowitz’s team trained the system to evaluate speed either on the basis of the number of total instructions or the processing time. Depending on the processor used and the number of values to be sorted, AlphaDev’s best algorithms took between 4% and 71% less time than did human algorithms. But when the algorithms were called multiple times to sort lists of one -quarter of a million values, the cumulative time saving was only 1–2%, because of other code it did not optimize.
To see where AlphaDev eked out its gains, the team took a closer look at its algorithms. They found two new tactics for sorting, which were called AlphaDev swap move and AlphaDev copy move. They are comparable to the move which AlphaGo, a predecessor to AlphaZero, made against the human Go champion Lee Sedol at an exhibition match. He says that it influenced how we thought about strategies, and that it was fundamental to winning the game.
The team at DeepMind would like to work on more problems, even the design of hardware, in the future. We want to tackle the whole stack.